Après le Snowflake Summit, Databricks a pris le relais au Data + AI Summit 2025 avec une évolution notable. La plateforme ne se limite plus à l’ingénierie ou à la science des données : elle se positionne désormais comme un système d’activation intelligent, où modèles, agents, pipelines et utilisateurs interagissent en temps réel, dans un cadre gouverné, fluide et conçu pour l’industrialisation à grande échelle.
Agent Bricks : l’interface devient acteur
Créer un agent IA était jusqu’alors un processus long et complexe. Avec Agent Bricks, Databricks simplifie cette tâche en offrant une expérience guidée, optimisée et prête pour la production. En déclarant simplement le besoin métier, l’outil génère automatiquement des tests, évalue la qualité via des LLM internes, et ajuste les paramètres pour optimiser la performance et le coût, tout en garantissant la sécurité grâce à Unity Catalog.
Comment ça fonctionne ?
- Déclare ton besoin métier
Tu définis en langage courant : « je veux extraire X de mes rapports PDF », « répondre à des questions sur mes SOP », etc., et tu connectes tes données. - Evaluation automatisée
Agent Bricks génère automatiquement des jeux de tests synthétiques et des juges LLM internalisés pour évaluer la qualité — précision, recall, co-linéarité… - Optimisation automatique
Il teste différentes stratégies — tuning prompts, fine-tuning, modèles LLM variés, récompense adaptative (ALHF)… — pour trouver le meilleur compromis performance/coût . Tu choisis ensuite ta version idéale : priorité à la qualité ou à l’efficacité.
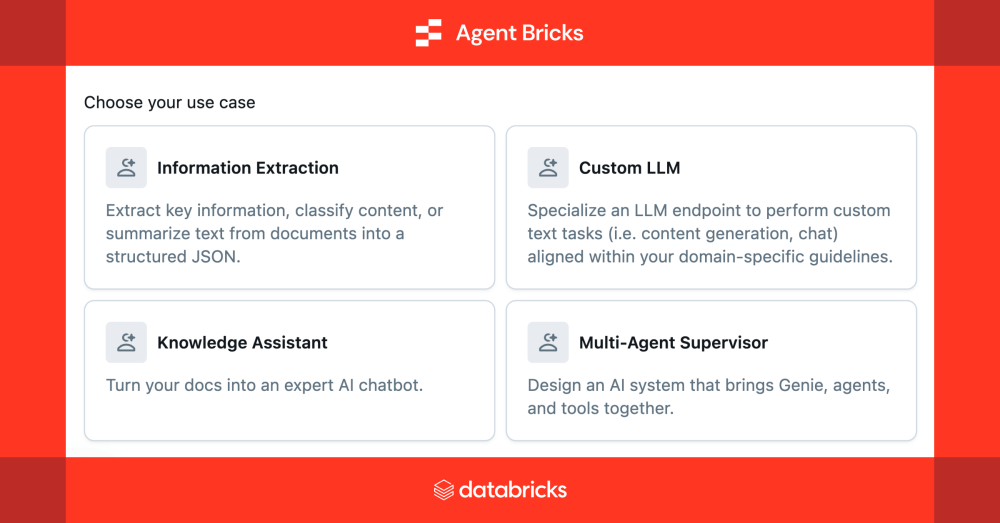
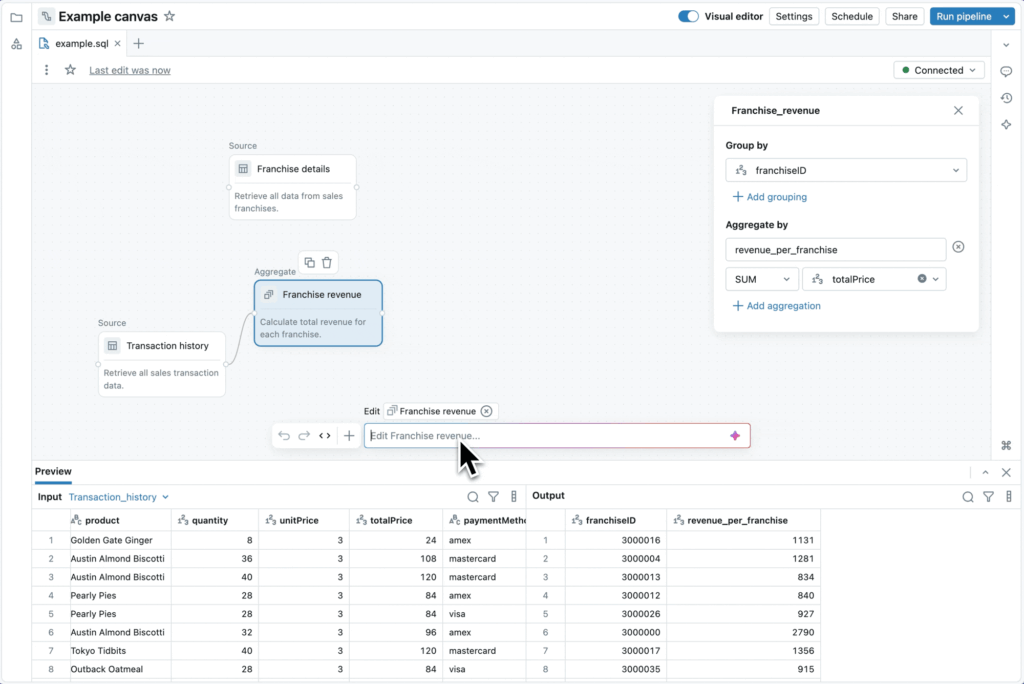
LakeFlow Designer : le pipeline devient produit
Avant, élaborer un pipeline ETL demandait du code, des outils multiples et des allers‑retours entre analystes et ingénieurs.
Avec Lakeflow Designer, tout devient visuel, accessible et collaboratif. En glissant-déposant des blocs ou en utilisant le langage naturel, un analyste construit un pipeline. Sous le capot, c’est du SQL standard compilé en Lakeflow Declarative Pipelines, versionné, surveillé et prêt pour la prod.
Le gros plus ? L’IA intégrée comprend le contexte métier (nom des tables, historique de requêtes), oriente automatiquement la construction, et assure la conformité avec Unity Catalog
Le résultat : un flux ETL industrial-ready en quelques minutes.
Unity Catalog Everywhere : gouvernance native, IA incluse
On le sait : l’avenir de la donnée passe par la gouvernance. Mais au lieu d’en faire une contrainte, Databricks l’intègre comme socle intelligent. Avec Unity Catalog, tout — absolument tout — est traçable, versionné, auditable. Données, notebooks, modèles, agents, prompts, API… même les requêtes IA générées en langage naturel.
La nouveauté 2026 ? L’arrivée de l’observabilité IA : chaque réponse produite par un agent est loggée, expliquée, reliée à sa source. On peut remonter le fil d’une décision automatisée, comprendre son raisonnement, corriger les biais… sans jamais quitter la plateforme.
MLflow 3.0 : le cycle IA devient produit
Jusqu’ici, piloter un projet IA (ML ou GenAI) relevait du parcours du combattant. D’un côté, des notebooks et des modèles qui vivent leur vie. De l’autre, des exigences métier (qualité, sécurité, coût) rarement traduites dans les workflows réels. Entre les deux ? Du code artisanal, des logs isolés, et beaucoup de non‑dit.
Avec MLflow 3.0, Databricks transforme cette fragmentation en une chaîne de valeur unifiée, gouvernée, observable.
Tout devient mesurable… et gouverné
Déploiement sécurisé, validé, industrialisé
Tu définis tes conditions de déploiement (score minimal, absence de contenu toxique, latence max…), et seules les versions validées passent en prod. Plus de push sauvage, place à une IA maîtrisée.
Traçabilité de bout en bout
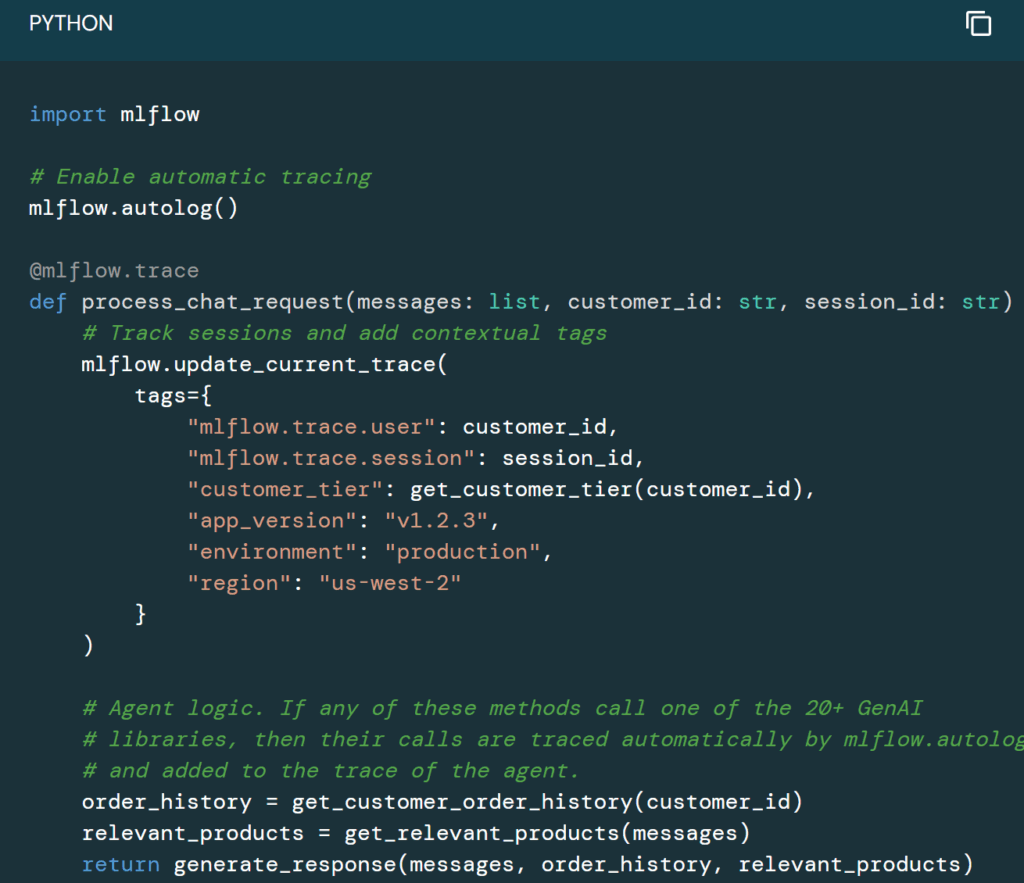
Chaque appel LLM est automatiquement tracé : prompt, réponse, temps de latence, coût, modèle utilisé… MLflow capture tout, y compris dans les apps GenAI type RAG ou assistants métiers. Tu sais ce qui a été fait, par qui, comment, et à quel coût.
Évaluation intégrée
Plus besoin d’évaluer « à la main » la pertinence d’une réponse. MLflow 3.0 intègre des LLM Judges pour scorer automatiquement les outputs : factualité, complétude, ton, sécurité, biais… Et tu peux créer tes propres métriques métier.
Feedback humain opérationnel
Grâce à Review App, les utilisateurs métier peuvent annoter, corriger, commenter une génération — et alimenter directement les boucles d’amélioration continue (fine-tuning ou réécriture de prompt).
Versioning natif des prompts et des modèles
MLflow 3.0 introduit un Prompt Registry avec comparaison visuelle, logs d’usage, scoring. Tu peux A/B tester des prompts comme tu testerais du code ou des modèles, avec gouvernance intégrée (Unity Catalog).
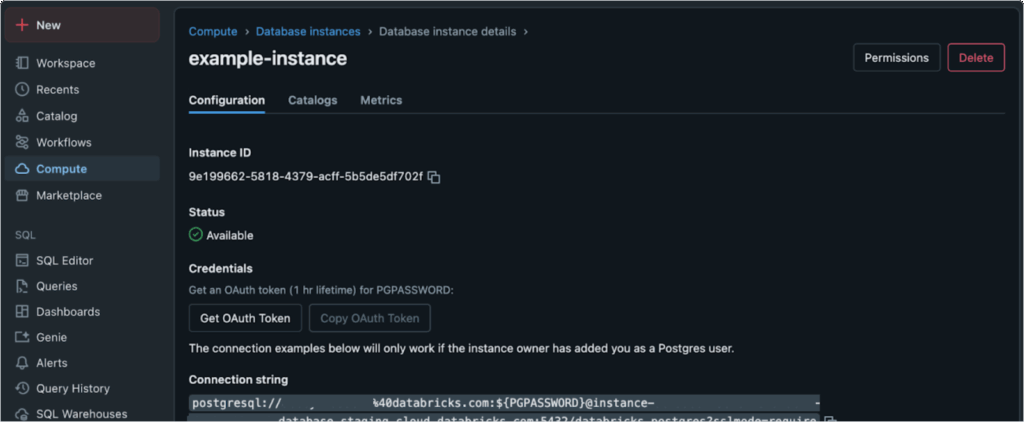
Lakebase : la base de données opérationnelle pour l’IA
Lakebase introduit une base de données compatible Postgres, entièrement gérée et optimisée pour les applications natives de l’IA. Elle permet d’unifier les charges de travail transactionnelles et analytiques, facilitant ainsi le développement d’applications intelligentes avec un accès en temps réel aux données, sans nécessiter de processus ETL complexes.
Avec cette édition du Summit, Databricks envoie un message clair : la donnée seule ne suffit plus. Il faut des agents capables d’en faire quelque chose, maintenant, dans le bon contexte, avec les bonnes règles, et à l’échelle de l’entreprise.
Lakebase, Agent Bricks, Unity Catalog, LakeFlow Designer, MLflow… Ce ne sont pas juste des features. Ce sont les briques d’un nouveau système d’intelligence continue.



0 commentaires